4.2 Primary manuscript figures recreated with estimates pooled using fixed effects
More estimates are significant when pooling using fixed effects due to the generally smaller confidence intervals.
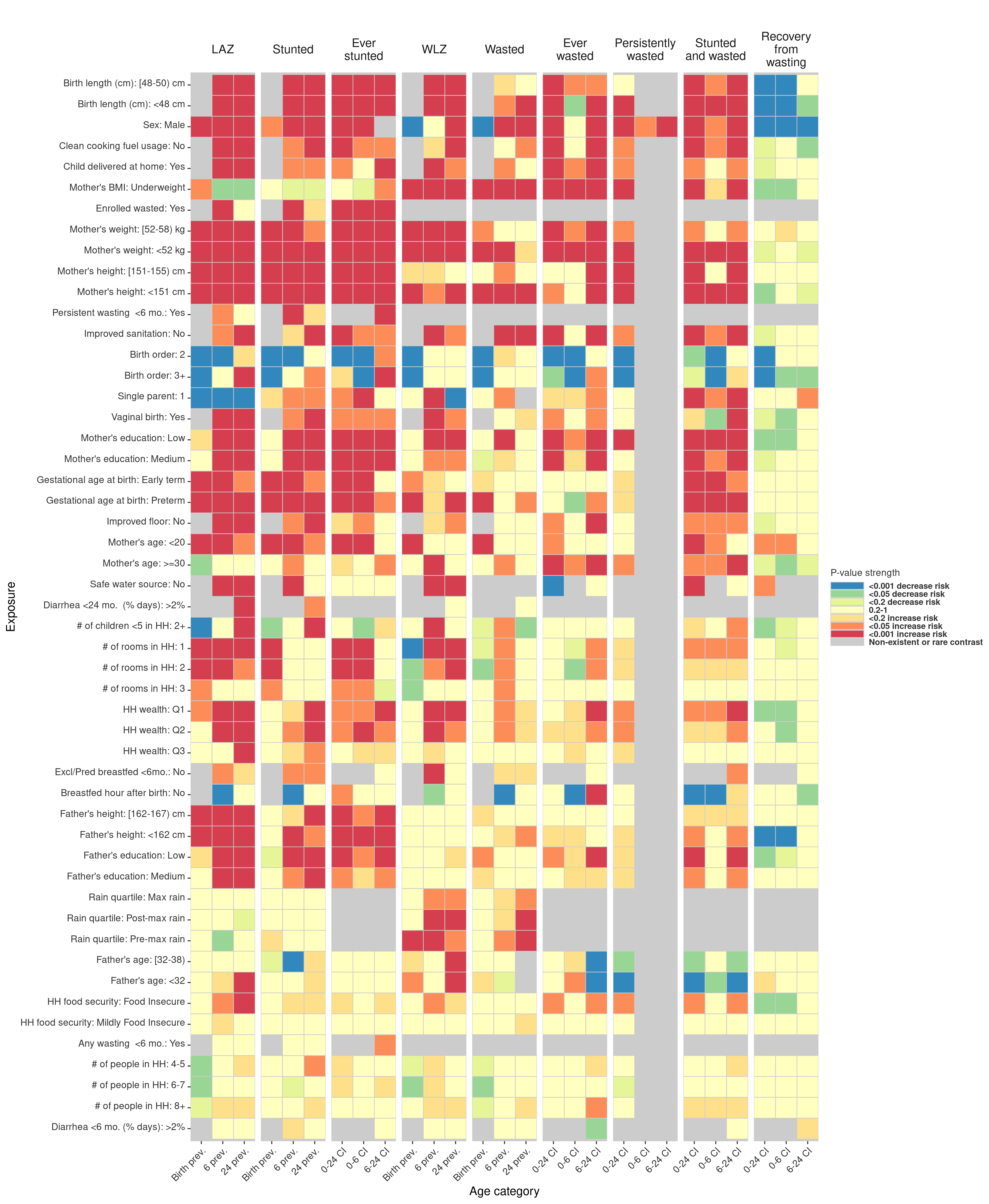 Figure 1a. Heatmap of significance and direction across exposure-outcome combinations of associations estimated using fixed effects.
Figure 1a. Heatmap of significance and direction across exposure-outcome combinations of associations estimated using fixed effects.
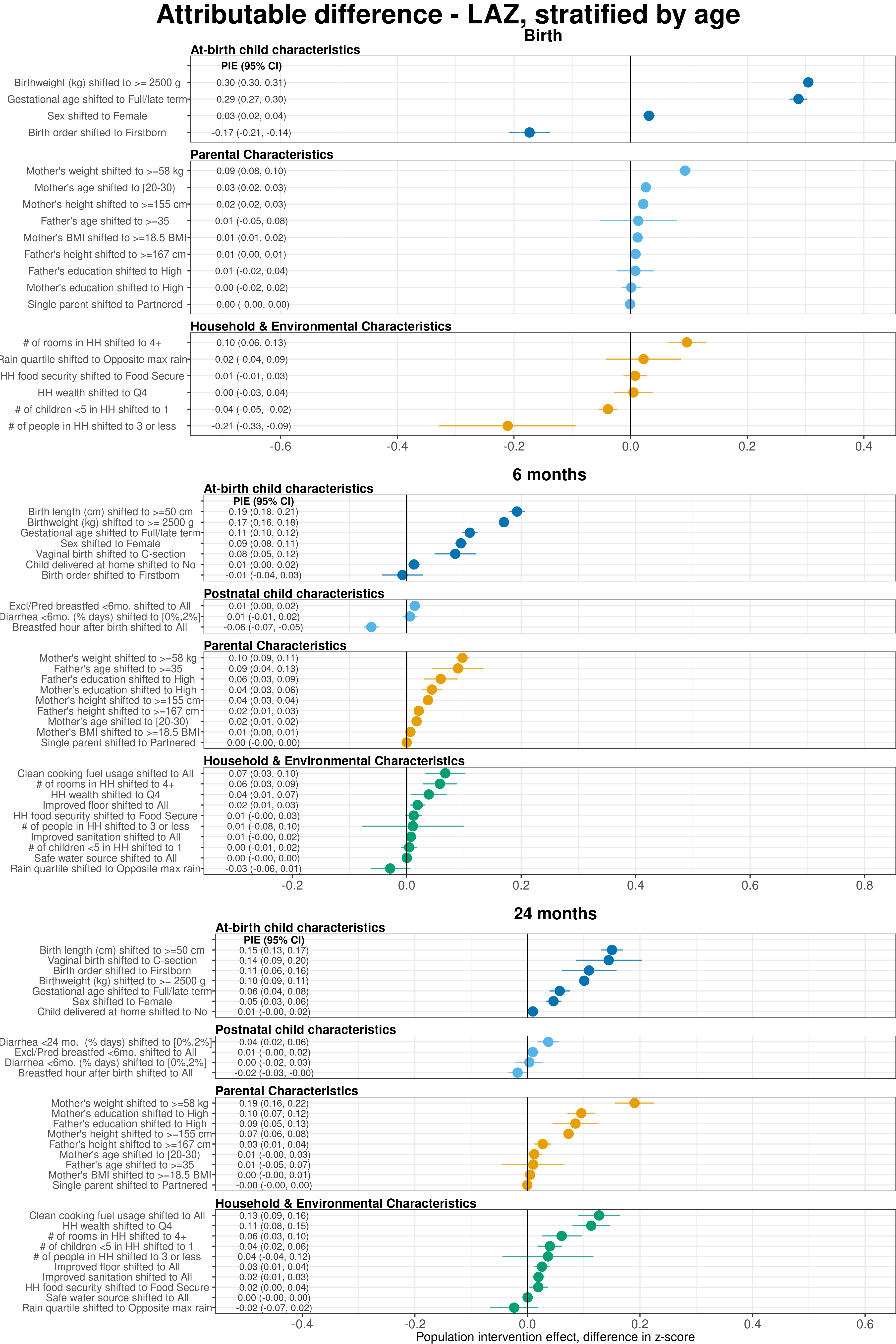 Extended Data Figure 3 | Age-stratified population attributable differences in length-for-age Z-scores estimated using fixed effects.
Extended Data Figure 3 | Age-stratified population attributable differences in length-for-age Z-scores estimated using fixed effects.
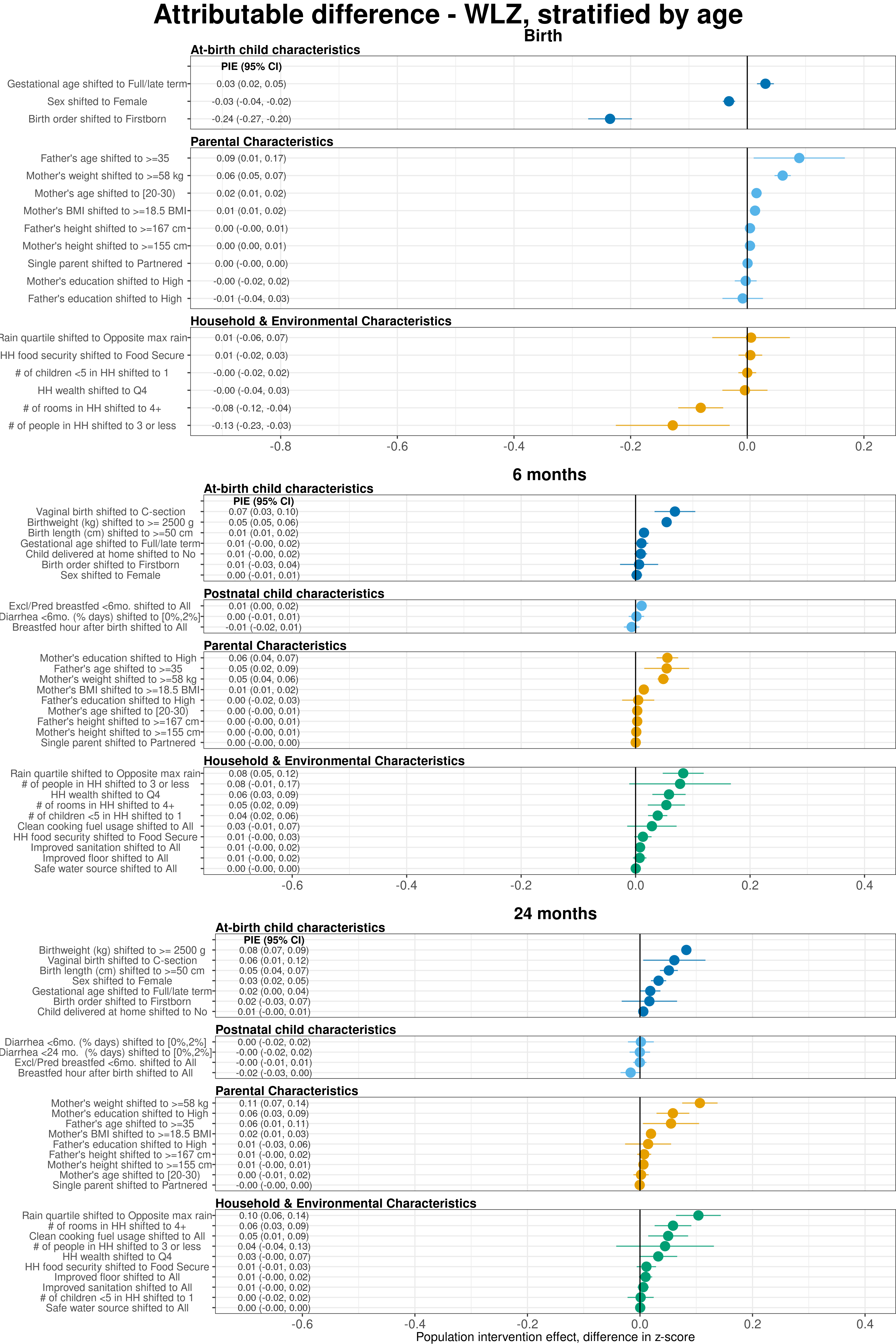 Extended Data Figure 4 | Age-stratified population attributable differences in weight-for-length Z-scores estimated using fixed effects.
Extended Data Figure 4 | Age-stratified population attributable differences in weight-for-length Z-scores estimated using fixed effects.
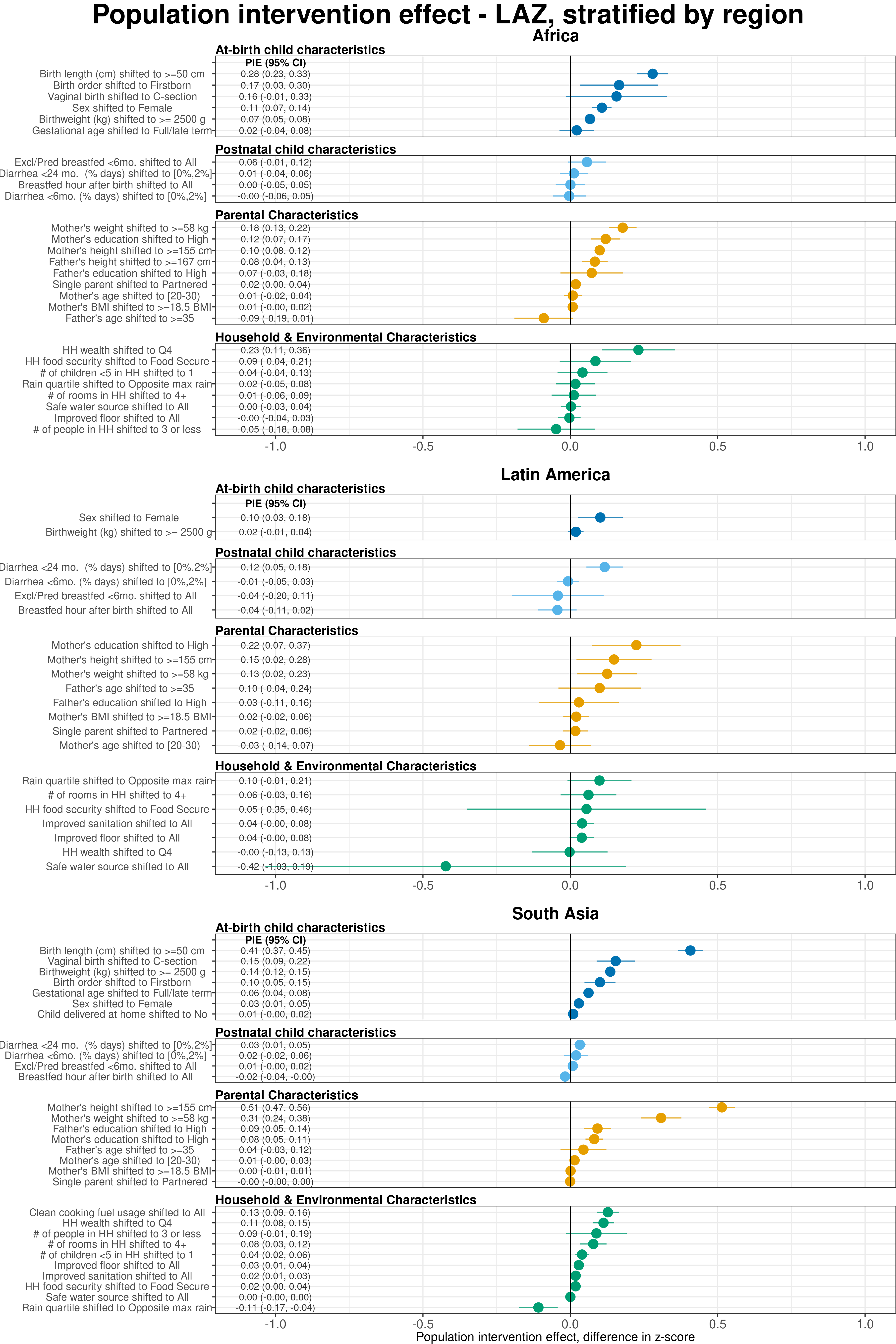 Extended Data Figure 7 | Region-stratified population attributable differences in length-for-age Z-scores estimated using fixed effects.
Extended Data Figure 7 | Region-stratified population attributable differences in length-for-age Z-scores estimated using fixed effects.
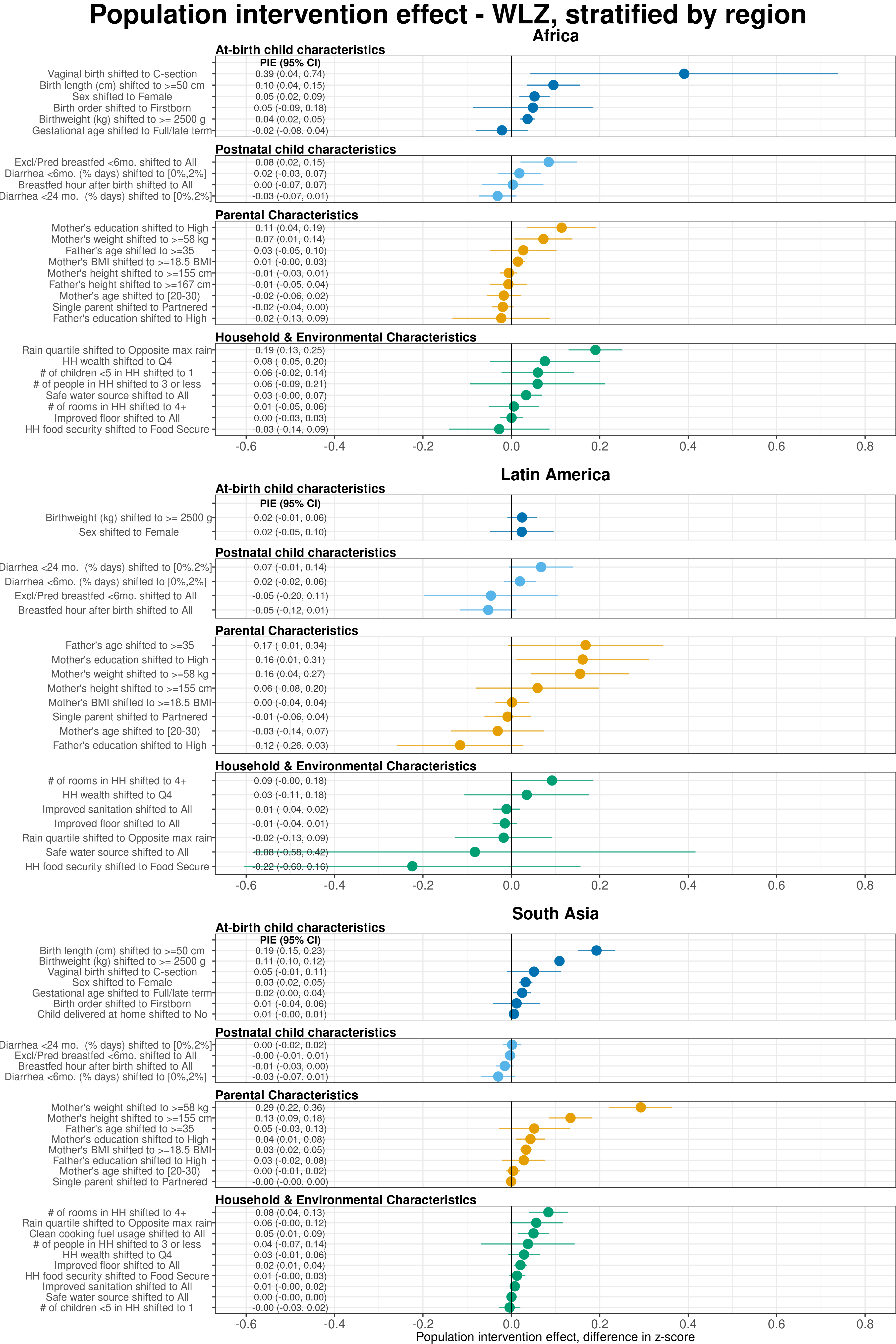 Extended Data Figure 8 | Region-stratified population attributable differences in weight-for-length Z-scores estimated using fixed effects.
Extended Data Figure 8 | Region-stratified population attributable differences in weight-for-length Z-scores estimated using fixed effects.